
正規分布表の定義
正規分布とは何ですか?
NS 正規分布 式は2つの単純なパラメータに基づいています—平均 と 標準偏差-特定のデータセットの特性を定量化します。
平均はデータセット全体の「中央」または平均値を示しますが、標準偏差はその平均値の周りのデータポイントの「広がり」または変動を示します。
重要なポイント
- 正規分布式は、特定のデータセットの特性を定量化する2つの単純なパラメーター(平均と標準偏差)に基づいています。
- 簡単な計算と実際の問題への適用のための統一された標準的な方法を容易にするために、 正規分布の一部を形成するZ値への標準変換が導入されました テーブル。
- 正規分布のプロパティは次のとおりです。正規曲線は平均に関して対称です。 平均は中央にあり、領域を半分に分割します。 曲線の下の総面積は、mean = 0およびstdev = 1の場合は1に等しくなります。 分布は、その平均と標準偏差によって完全に記述されます。
- 正規分布表は、上昇トレンドまたは下降トレンド、サポートまたはレジスタンスレベル、およびその他の技術的指標を特定するために証券取引で使用されます。
正規分布の例
次の2つのデータセットについて考えてみます。
- データセット1 = {10、10、10、10、10、10、10、10、10、10}
- データセット2 = {6、8、10、12、14、14、12、10、8、6}
Dataset1の場合、平均= 10および標準偏差(stddev)= 0です。
Dataset2の場合、平均= 10および標準偏差(stddev)= 2.83です。
DataSet1のこれらの値をプロットしてみましょう。

DataSet2の場合も同様です。

赤い 水平線 上記の両方のグラフで、各データセットの「平均」または平均値を示しています(どちらの場合も10)。 2番目のグラフのピンク色の矢印は、平均値からのデータ値の広がりまたは変動を示しています。 これは、DataSet2の場合の標準偏差値2.83で表されます。 DataSet1の値はすべて同じ(それぞれ10)であり、変動がないため、stddev値はゼロであり、ピンク色の矢印は適用されません。
stddev値には、データ分析に非常に役立ついくつかの重要で有用な特性があります。 正規分布の場合、データ値は平均の両側に対称的に分布します。 正規分布のデータセット、横軸に標準偏差、縦軸にデータ値の数をプロットしたグラフの場合、次のグラフが得られます。

正規分布のプロパティ
- 正規曲線は平均に関して対称です。
- 平均は中央にあり、領域を2つに分割します。
- 曲線の下の総面積は、mean = 0およびstdev = 1の場合は1に等しくなります。
- 分布は、その平均と標準偏差によって完全に記述されます
上のグラフからわかるように、stddevは次のことを表しています。
- 68.3% データ値の範囲内 1標準偏差 平均の(-1から+1)
- 95.4% データ値の範囲内 2標準偏差 平均の(-2から+2)
- 99.7% データ値の範囲内 3標準偏差 平均の(-3から+3)
ベル型の曲線の下の領域は、測定されると、特定の範囲の望ましい確率を示します。
- X未満: 例えば データ値が70未満である確率
- Xより大きい: 例えば データ値が95を超える確率
- Xの間1 およびX2: 例えば 65から85の間のデータ値の確率
ここで、Xは対象の値です(以下の例)。
データセットが異なれば平均値と標準偏差値も異なるため、面積のプロットと計算は必ずしも便利ではありません。 計算を容易にし、実際の問題に適用できるようにするための統一された標準的な方法を容易にするために、Z値への標準的な変換が導入されました。 正規分布表.
Z =(X –平均)/ stddev、ここでXは 確率変数.
基本的に、この変換により、平均と標準偏差がそれぞれ0と1に標準化されます。これにより、標準で定義されたZ値のセットが有効になります。 正規分布表)簡単な計算に使用します。 確率値を含む標準のz値テーブルのスナップショットは次のとおりです。
|
z |
0.00 |
0.01 |
0.02 |
0.03 |
0.04 |
0.05 |
0.06 |
|
0.0 |
0.00000 |
0.00399 |
0.00798 |
0.01197 |
0.01595 |
0.01994 |
… |
|
0.1 |
0.0398 |
0.04380 |
0.04776 |
0.05172 |
0.05567 |
0.05966 |
… |
|
0.2 |
0.0793 |
0.08317 |
0.08706 |
0.09095 |
0.09483 |
0.09871 |
… |
|
0.3 |
0.11791 |
0.12172 |
0.12552 |
0.12930 |
0.13307 |
0.13683 |
… |
|
0.4 |
0.15542 |
0.15910 |
0.16276 |
0.16640 |
0.17003 |
0.17364 |
… |
|
0.5 |
0.19146 |
0.19497 |
0.19847 |
0.20194 |
0.20540 |
0.20884 |
… |
|
0.6 |
0.22575 |
0.22907 |
0.23237 |
0.23565 |
0.23891 |
0.24215 |
… |
|
0.7 |
0.25804 |
0.26115 |
0.26424 |
0.26730 |
0.27035 |
0.27337 |
… |
|
… |
… |
… |
… |
… |
… |
… |
… |
0.239865のz値に関連する確率を見つけるには、最初に小数点以下2桁(つまり0.24)に丸めます。 次に、行の最初の2桁の有効数字(0.2)と、列の最下位桁(残りの0.04)を確認します。 これにより、0.09483の値になります。
確率値(負の値を含む)の小数点以下5桁までの精度を持つ、完全な正規分布表を見つけることができます。 ここ.
実際の例をいくつか見てみましょう。 大規模なグループの個人の身長は、正規分布パターンに従います。 高さが記録され、平均と標準偏差がそれぞれ66インチと6インチに計算された100人の個人のセットがあると仮定します。
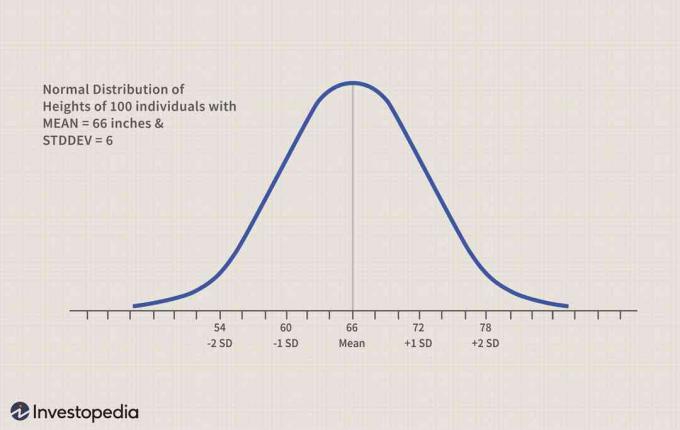
z値テーブルを使用して簡単に答えることができるいくつかのサンプル質問を次に示します。
グループ内の人が70インチ以下である確率はどれくらいですか?
質問は見つけることです の累積値 P(X <= 70)、つまり100のデータセット全体で、0から70までの値の数。
まず、70のX値を同等のZ値に変換しましょう。
Z =(X –平均)/ stddev =(70-66)/ 6 = 4/6 = 0.66667 = 0.67(小数点以下第2位を四捨五入)
ここで、P(Z <= 0.67)= 0を見つける必要があります。 24857(上記のzテーブルから)
つまり、グループ内の個人が70インチ以下になる確率は24.857%です。
しかし、ちょっと待ってください。上記は不完全です。 70まで、つまり0から70までのすべての可能な高さの確率を探していることを忘れないでください。 上記は、平均値から目的の値(つまり、66から70)までの部分を示しています。 正解に到達するには、残りの半分(0から66)を含める必要があります。
0から66は半分の部分(つまり、1つの極端な平均から中間の平均)を表すため、その確率は単純に0.5です。
したがって、人が70インチ以下である正しい確率= 0.24857 + 0.5 = 0です。 74857 = 74.857%
グラフィカルに(面積を計算することにより)、これらはソリューションを表す2つの合計領域です。

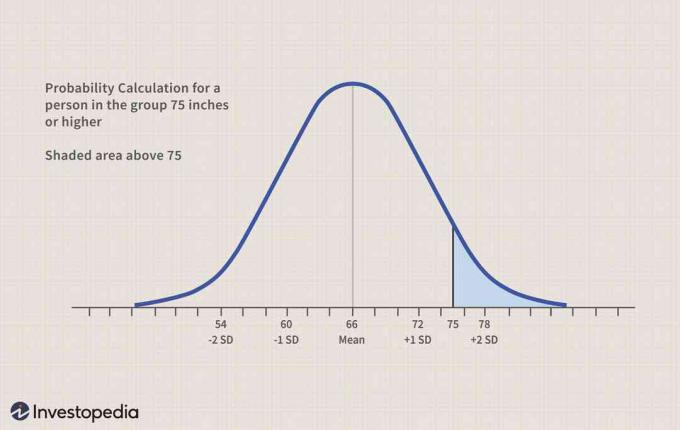
人が75インチ以上である確率はどれくらいですか?
つまり、検索 補完的な累積 P(X> = 75)。
Z =(X –平均)/ stddev =(75-66)/ 6 = 9/6 = 1.5。
P(Z> = 1.5)= 1- P(Z <= 1.5)= 1 –(0.5 + 0.43319)= 0.06681 = 6.681%
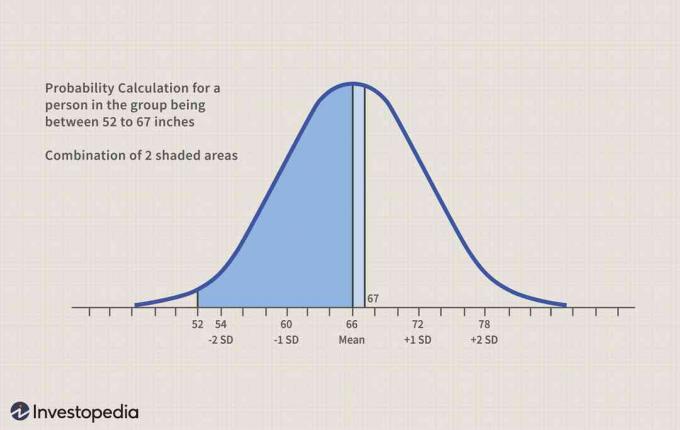
人が52インチから67インチの間にいる確率はどれくらいですか?
P(52 <= X <= 67)を見つけます。
P(52 <= X <= 67)= P [(52-66)/ 6 <= Z <=(67-66)/ 6] = P(-2.33 <= Z <= 0.17)
= P(Z <= 0.17)–P(Z <= -0.233)=(0.5 + 0.56749)-(。40905)=
この正規分布表(およびz値)は、一般に、 株式市場 株式とインデックスの場合。 それらは範囲ベースの取引で使用され、識別します 上昇トレンド また 下降トレンド, サポートまたは抵抗 レベル、およびその他 技術指標 平均と標準偏差の正規分布の概念に基づいています。